
| PROJEKT |
|
|||||||||||||||
| Oprogramowanie MicroFlow | |||||||||||||||
| Już wkrótce nowa wersja kodu oferująca pełną funkcjonalność oraz zupełnie nowe możliwości. Po dopracowaniu szczegułów i wyczyszczeniu kodu zostanie udostępniona na zasadach Open Source | |||||||||||||||
| Opracowana została nowa wersja programu Microflow z akceleracją obliczeń na procesorach graficznych z wykorzystaniem biblioteki CUDA. | |||||||||||||||
| Ze względu na cechy architektury GPU (ograniczona pamięć i wektorowy model przetwarzania) oraz planowane wykorzystanie do symulacji przypadków zawierających dużą liczbę węzłów "pustych" kod w wersji GPU wykorzystuje zupełnie inne struktury danych, niż wersja CPU. Podczas opracowywania wersji GPU duży nacisk położono na jak najmniejsze wykorzystanie pamięci GPU, ograniczenie obciążenia magistrali pamięci GPU i możliwość łatwego pomijania węzłów pustych. W celu spełnienia tych założeń użyto rozwiązania opartego na podziale domeny przypadku na kwadratowe poddomeny zawierające 16 x 16 węzłów LBM, dla których obliczenia są przeprowadzane niezależnie i równolegle pod warunkiem zapewnienia możliwości uzgadniania wartości na krawędziach po wykonaniu pojedynczej iteracji. Pozwoliło to na łatwe wyeliminowanie większości węzłów "pustych" (bloki zawierające wyłącznie takie węzły mogą zostać wyeliminowane podczas tworzenia struktury danych) i efektywne wykorzystanie technik przetwarzania wektorowego (rozmiar wszystkich bloku jest jednakowy i dostosowany do struktury sprzętu). Niskie obciążenie magistrali pamięci GPU uzyskano dzięki takiemu przeorganizowaniu obliczeń, w którym dane na początku iteracji są kopiowane do tymczasowych buforów wewnątrz GPU (rejestrów i pamięci współdzielonej), następnie obliczenia są wykonywane na lokalnych kopiach, zapis zaś jest przeprowadzany jednorazowo po wykonaniu wszystkich obliczeń. |
|||||||||||||||
| W trakcie prac nad wersją GPU : zaimplementowano właściwy silnik obliczeniowy dla GPU zawierający komplet obliczeń LBM, zaimplementowano algorytm podziału domeny na bloki zawierające 162 węzłów każdy i eliminacji bloków "pustych". Wynik podziału może dodatkowo być zapisany na dysku w postaci pliku graficznego w formacie png (wykorzystano biblioteki libpng i png++), zaimplementowano mechanizm wczytywania parametrów konfiguracyjnych programu ze skryptów w języku Ruby, co pozwala na bardzo dużą elastyczność generowania parametrów (plik konfiguracyjny może być standardowym programem w języku Ruby, czyli wartości parametrów można obliczać w praktycznie dowolny sposób), Przeprowadzono szereg optymalizacji kodu zwiększających wydajność obliczeń o ok. 40% w stosunku do pierwotnej wersji GPU (na procesorze GTX TITAN). Bieżąca wydajność to odpowiednio 1060 MLUPS i 1020 MLUPS dla modeli BGK incompressible i quasicompressible oraz 920 MLUPS i 865 MLUPS dla modeli MRT incompressible i quasicompressible. Głównym czynnikiem ograniczającym wydajność jest przepustowość pamięci (obecna wersja wykorzystuje ok 65% maksymalnej przepustowości pamięci dostępnej na karcie GTX TITAN). Zaimplementowany kod źródłowy składa się z 73 plików źródłowych zawierających łącznie ok. 8 tysięcy linii kodu. |
|||||||||||||||
| Poniżej zaprezentowano kilka przykładowych rysunków obrazujących możliwości oprobramowania Microflow | |||||||||||||||
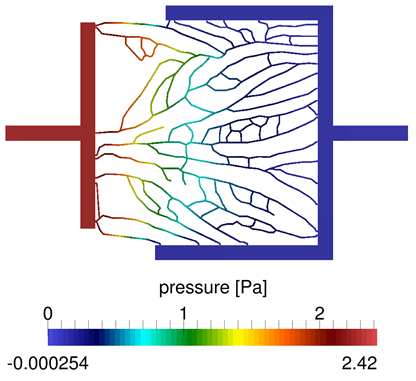 |
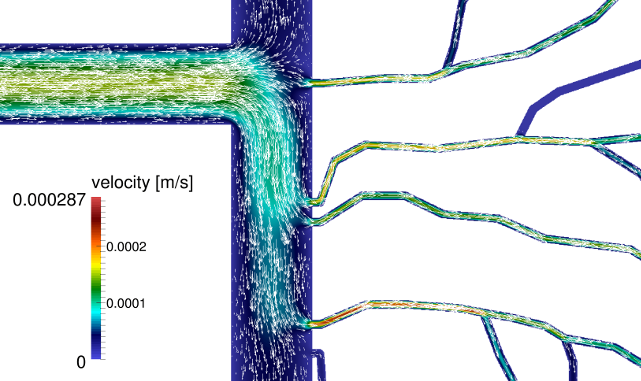 |
||||||||||||||
| A) | B) | ||||||||||||||
| A - spadek ciśnienia w sieci mikrokanałów, B - rozkłady prędkości płynu w mikrokanałach. | |||||||||||||||